FAIR Data
The FAIR Data Principles were first introduced in 2016 by an international group of data experts led by Mark D. Wilkinson, with contributors from academia, industry, funding agencies, and publishers. Their paper, “The FAIR Guiding Principles for Scientific Data Management and Stewardship” [1], emerged from discussions within the Force11 community, a network advocating for better scholarly communication in the digital age. The initiative was supported by organizations such as the European Commission, GO FAIR, and the Research Data Alliance (RDA).
The central motivation was to address a growing problem: while vast amounts of research data were being produced, they were often stored in inaccessible formats or local silos, making them difficult to find, reuse, or integrate across disciplines.
The FAIR framework was therefore designed to make data not just open, but also machine-actionable, ensuring that both humans and computers can find, access, combine, and reuse scientific data in a sustainable and standardized way.
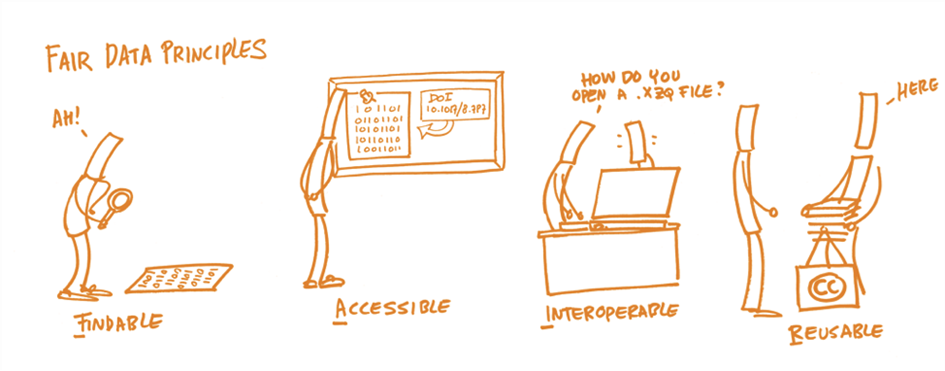
Image source: https://book.fosteropenscience.eu/
FAIR stands for Findable, Accessible, Interoperable, and Reusable. The FAIR principles help researchers make their data easy to find, access, combine, and reuse - by both humans and machines.
Findable: Your data should be easy to find and to locate.
In practice:
- Assign a persistent identifier (e.g. DOI) to your dataset.
- Provide rich metadata (author, title, date, keywords, methods, etc.) to your DOI.
- Register data in searchable repositories (e.g. Zenodo, PANGAEA, OSF).
- Cross-link your data and publications.
Accessible: Your data and metadata should be retrievable using open, standardized protocols.
In practice:
- Deposit data in trusted repositories that support HTTP, HTTPS, or FTP.
- Ensure metadata remain available, even if the data itself is restricted.
- Avoid paywalls or unnecessary technical barriers.
- Use authentication and authorization systems if you need to restrict access (e.g. for sensitive data).
Interoperable: Your data should be exchangeable with other datasets and tools, or infrastructures.
In practice:
- Use open, non-proprietary formats (e.g. CSV, TXT, XML instead of XLSX).
- Follow community standards (ontologies, vocabularies, or thesauri).
- Structure your data in a tidy format (one variable per column, one observation per row).
- Document the formal and semantic structure of your data clearly.
Examples: In the life sciences, the ISA model or ARC framework (DataPLANT initiative) supports interoperability through structured annotation. The Data Documentation Initiative (DDI) offers guidance for structuring and documenting datasets in the social sciences.
Reusable: Your data should include enough context and licensing information to be used again.
In practice:
- Add clear usage licenses (e.g. CC BY, CC0) to signal reuse rights.
- Document provenance: how, when, and by whom data were created.
- Provide detailed documentation for all processing steps.
- Define embargo periods or usage restrictions if needed.
- Link your data with related outputs (e.g. code, publications, grey literature).
Why should FAIR matter to you?
Applying FAIR principles to your data increases:
- The visibility and impact of your research.
- Trust and transparency in your data.
- The reproducibility of scientific results.
- The efficiency of future research through data reuse.
Further references
[1] Wilkinson, M. et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. Scientific Data, 3, DOI: https://doi.org/10.1038/sdata.2016.18
[2] Banerjee, S. (2025). A Guide to the FAIR Principles. https://openscience.eu/article/infrastructure/guide-fair-principles
[3] FORCE11: Guiding Principles for Findable, Accessible, Interoperable and Re-usable Data Publishing. URL: https://force11.org/info/the-fair-data-principles/
[4] GO FAIR Initiative (2018). FAIR Principles. URL: https://www.go-fair.org/fair-principles/
[5] SURF (2019). FAIR Data Advanced Use Cases: From Principles to Practice.